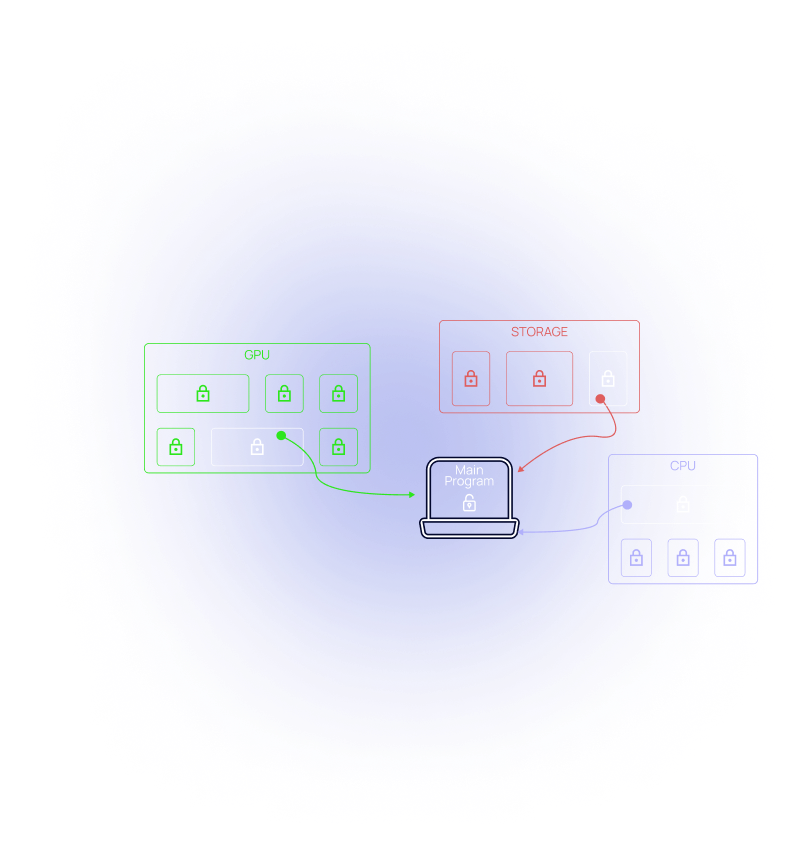
Protect data at rest, in flight and in-use, with computation performed in software defined trusted execution environments. PrimeLab’s proprietary VM isolation technology fragments virtual machines, their processes & keys across multiple actors. Powering Initiator centric security where anyone can control their own tamper proof, private workload no matter whose machine it’s running on.
Beyond increasing invest-ability by lowering the economic risk of model leakage. Confidential compute increases model training & inference efficiencies on the order of reducing a $90K AWS workload to $200.
Confidentiality
No actor knows what they’re doing or for whom. Until a workload is pieced back together by its initiator, anyone who sniffs a portion of a secure workload receives only garbage. Multiple workloads run on the same actor without the ability to peer inside each other. AI models are split up and stored closer to end users for faster inference response times without the risk of model theft.
Integrity
Programs & results can not be tampered with. Attestation cryptographically hashes programs during execution to confirm they are identical to their initial state. The attestation is included with the program outputs to confirm they were generated by trusted code. Should the attestation fail the program is terminated and reset. Attestation creates a software bill of materials where future programs know where and when every bit was processed and with what code.
Availability
A confidential compute network composes its own availability to match compute demand with available hardware. PrimeLab uses a pre-pay lock encryption key to forecast demand and incentivize new hardware participation & scaling. Embedded real-time payments included with every server call to pay incrementally for compute enables unparalleled efficiencies.
Confidential Compute for AI
Beyond increasing invest-ability by lowering the economic risk of model leakage. Confidential compute increases model training & inference efficiencies on the order of reducing a $90K AWS workload to $200.
Data shaping without decryption
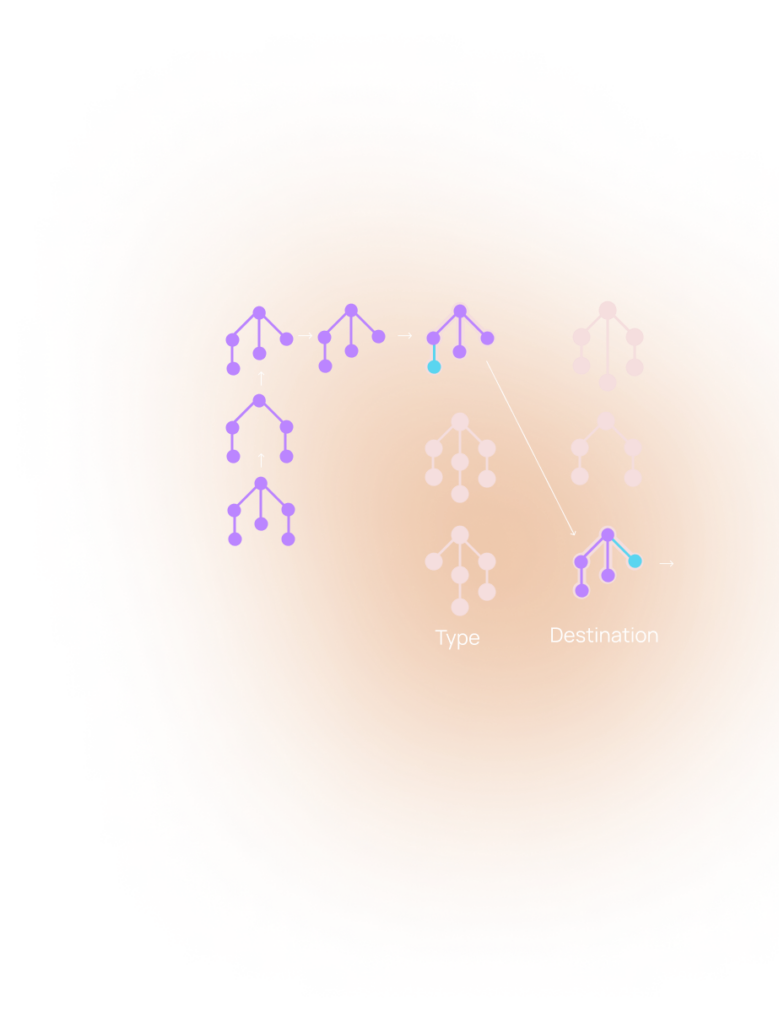
Based on the edging of our Proprietary Binary Encoding the network can determine if a message contains shopping data, health data, etc … without decrypting the message itself. This creates incredibly efficient routing of data through AI models during training.
Reducing inference response times
Confidential compute breaks up and stores models across multiple actors closer to end users. Combined with data shaping without decryption, the network routes messages more efficiency to the correct portion of an AI model for faster inference. Bloom AI has proven demand for distributed inference, however without efficient routing their responses are slower than OpenAI (Who themselves writes out every word to distract from the fact it takes 2-3 minutes to receive an answer). Efficient routing to models on actors located within milliseconds of end users
Shared Workloads & Resource Management
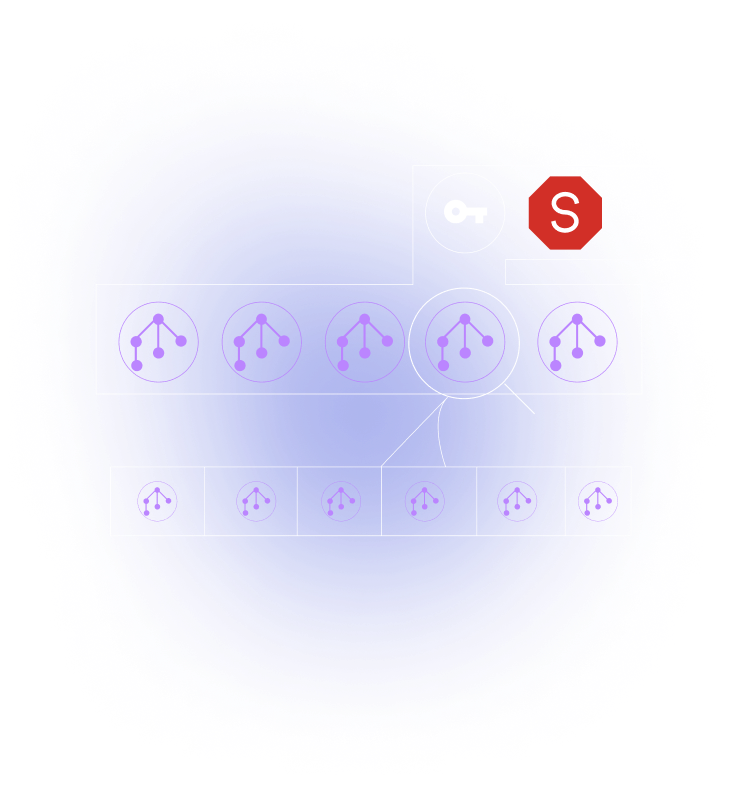
Rather than purchasing a $50M super computer, allocate a portion of a shared resource or rent your resource to others. Every device on the network is benchmarked to test its RAM, CPU, GPU, Storage & Latency to the limit (wether a cellphone at the edge or a Nvidia H100. Once benchmarked, confidential compute automatically selects and routes workloads that match the devices capabilities. All programs are different, a game of Tic-Tac-Toe & a protein folding simulation each require specialized hardware and having initially indicated their requirements are assigned hardware as such.
Try Our Technology
Try our technology for yourself on your own device. Based on Kerchiefs Principle that a system’s security should not depend on its secrecy, we’ve published our technology in a demo application for anyone to inspect. Please contact us with questions.